
All Problems
13 problems1
Number of Islands
Given a 2D grid `grid` where `'1'` represents land and `'0'` represents water, count and return the number of islands.
An **island** is formed by connecting adjacent lands horizontally or vertically and is surrounded by water. You may assume water is surrounding the grid (i.e., all the edges are water).
**Example 1:**
```java
Input: grid = [
["0","1","1","1","0"],
["0","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
Output: 1
```
**Example 2:**
```java
Input: grid = [
["1","1","0","0","1"],
["1","1","0","0","1"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
Output: 4
```
**Constraints:**
* `1 <= grid.length, grid[i].length <= 100`
* `grid[i][j]` is `'0'` or `'1'`.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m * n)</code> time and <code>O(m * n)</code> space, where <code>m</code> is the number of rows and <code>n</code> is the number of columns in the grid.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
An island is a group of <code>1</code>'s in which every <code>1</code> is reachable from any other <code>1</code> in that group. Can you think of an algorithm that can find the number of groups by visiting a group only once? Maybe there is a recursive way of doing it.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse each group independently. We iterate through each cell of the grid. When we encounter a <code>1</code>, we perform a DFS starting at that cell and recursively visit every other <code>1</code> that is reachable. During this process, we mark the visited <code>1</code>'s as <code>0</code> to ensure we don't revisit them, as they belong to the same group. The number of groups corresponds to the number of islands.
</p>
</details>
Medium
Not Attempted
Video
2
Max Area of Island
You are given a matrix `grid` where `grid[i]` is either a `0` (representing water) or `1` (representing land).
An island is defined as a group of `1`'s connected horizontally or vertically. You may assume all four edges of the grid are surrounded by water.
The **area** of an island is defined as the number of cells within the island.
Return the maximum **area** of an island in `grid`. If no island exists, return `0`.
**Example 1:**
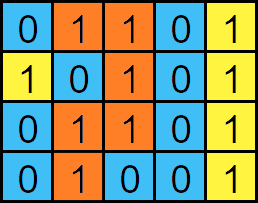
```java
Input: grid = [
[0,1,1,0,1],
[1,0,1,0,1],
[0,1,1,0,1],
[0,1,0,0,1]
]
Output: 6
```
Explanation: `1`'s cannot be connected diagonally, so the maximum area of the island is `6`.
**Constraints:**
* `1 <= grid.length, grid[i].length <= 50`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m * n)</code> time and <code>O(m * n)</code> space, where <code>m</code> is the number of rows and <code>n</code> is the number of columns in the grid.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
An island is a group of <code>1</code>'s in which every <code>1</code> is reachable from any other <code>1</code> in that group. Can you think of an algorithm that can find the number of groups by visiting a group only once? Maybe there is a recursive way of doing it.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse each group by starting at a cell with <code>1</code> and recursively visiting all the cells that are reachable from that cell and are also <code>1</code>. Can you think about how to find the area of that island? How would you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We traverse the grid, and when we encounter a <code>1</code>, we initialize a variable <code>area</code>. We then start a DFS from that cell to visit all connected <code>1</code>'s recursively, marking them as <code>0</code> to indicate they are visited. At each recursion step, we increment <code>area</code>. After completing the DFS, we update <code>maxArea</code>, which tracks the maximum area of an island in the grid, if <code>maxArea < area</code>. Finally, after traversing the grid, we return <code>maxArea</code>.
</p>
</details>
Medium
Not Attempted
Video
3
Clone Graph
Given a node in a connected undirected graph, return a deep copy of the graph.
Each node in the graph contains an integer value and a list of its neighbors.
```java
class Node {
public int val;
public List<Node> neighbors;
}
```
The graph is shown in the test cases as an adjacency list. **An adjacency list** is a mapping of nodes to lists, used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
For simplicity, nodes values are numbered from 1 to `n`, where `n` is the total number of nodes in the graph. The index of each node within the adjacency list is the same as the node's value (1-indexed).
The input node will always be the first node in the graph and have `1` as the value.
**Example 1:**
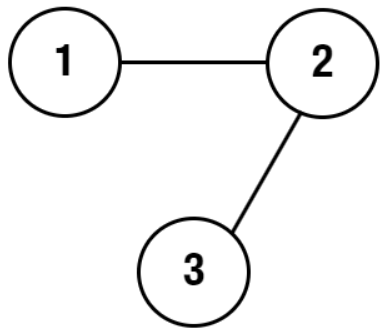
```java
Input: adjList = [[2],[1,3],[2]]
Output: [[2],[1,3],[2]]
```
Explanation: There are 3 nodes in the graph.
Node 1: val = 1 and neighbors = [2].
Node 2: val = 2 and neighbors = [1, 3].
Node 3: val = 3 and neighbors = [2].
**Example 2:**

```java
Input: adjList = [[]]
Output: [[]]
```
Explanation: The graph has one node with no neighbors.
**Example 3:**
```java
Input: adjList = []
Output: []
```
Explanation: The graph is empty.
**Constraints:**
* `0 <= The number of nodes in the graph <= 100`.
* `1 <= Node.val <= 100`
* There are no duplicate edges and no self-loops in the graph.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(V + E)</code> time and <code>O(E)</code> space, where <code>V</code> is the number of vertices and <code>E</code> is the number of edges in the given graph.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
We are given only the reference to the node in the graph. Cloning the entire graph means we need to clone all the nodes as well as their child nodes. We can't just clone the node and its neighbor and return the node. We also need to clone the entire graph. Can you think of a recursive way to do this, as we are cloning nodes in a nested manner? Also, can you think of a data structure that can store the nodes with their cloned references?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm. We use a hash map to map the nodes to their cloned nodes. We start from the given node. At each step of the DFS, we create a node with the current node's value. We then recursively go to the current node's neighbors and try to clone them first. After that, we add their cloned node references to the current node's neighbors list. Can you think of a base condition to stop this recursive path?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We stop this recursive path when we encounter a node that has already been cloned or visited. This DFS approach creates an exact clone of the given graph, and we return the clone of the given node.
</p>
</details>
Medium
Not Attempted
Video
4
Islands and Treasure
You are given a $m \times n$ 2D `grid` initialized with these three possible values:
1. `-1` - A water cell that *can not* be traversed.
2. `0` - A treasure chest.
3. `INF` - A land cell that *can* be traversed. We use the integer `2^31 - 1 = 2147483647` to represent `INF`.
Fill each land cell with the distance to its nearest treasure chest. If a land cell cannot reach a treasure chest then the value should remain `INF`.
Assume the grid can only be traversed up, down, left, or right.
Modify the `grid` **in-place**.
**Example 1:**
```java
Input: [
[2147483647,-1,0,2147483647],
[2147483647,2147483647,2147483647,-1],
[2147483647,-1,2147483647,-1],
[0,-1,2147483647,2147483647]
]
Output: [
[3,-1,0,1],
[2,2,1,-1],
[1,-1,2,-1],
[0,-1,3,4]
]
```
**Example 2:**
```java
Input: [
[0,-1],
[2147483647,2147483647]
]
Output: [
[0,-1],
[1,2]
]
```
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 100`
* `grid[i][j]` is one of `{-1, 0, 2147483647}`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m * n)</code> time and <code>O(m * n)</code> space, where <code>m</code> is the number of rows and <code>n</code> is the number of columns in the given grid.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would be to iterate on each land cell and run a BFS from that cells to find the nearest treasure chest. This would be an <code>O((m * n)^2)</code> solution. Can you think of a better way? Sometimes it is not optimal to go from source to destination.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can see that instead of going from every cell to find the nearest treasure chest, we can do it in reverse. We can just do a BFS from all the treasure chests in grid and just explore all possible paths from those chests. Why? Because in this approach, the treasure chests self mark the cells level by level and the level number will be the distance from that cell to a treasure chest. We don't revisit a cell. This approach is called <code>Multi-Source BFS</code>. How would you implement it?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We insert all the cells <code>(row, col)</code> that represent the treasure chests into the queue. Then, we process the cells level by level, handling all the current cells in the queue at once. For each cell, we mark it as visited and store the current level value as the distance at that cell. We then try to add the neighboring cells (adjacent cells) to the queue, but only if they have not been visited and are land cells.
</p>
</details>
Medium
Not Attempted
Video
5
Rotting Fruit
You are given a 2-D matrix `grid`. Each cell can have one of three possible values:
* `0` representing an empty cell
* `1` representing a fresh fruit
* `2` representing a rotten fruit
Every minute, if a fresh fruit is horizontally or vertically adjacent to a rotten fruit, then the fresh fruit also becomes rotten.
Return the minimum number of minutes that must elapse until there are zero fresh fruits remaining. If this state is impossible within the grid, return `-1`.
**Example 1:**
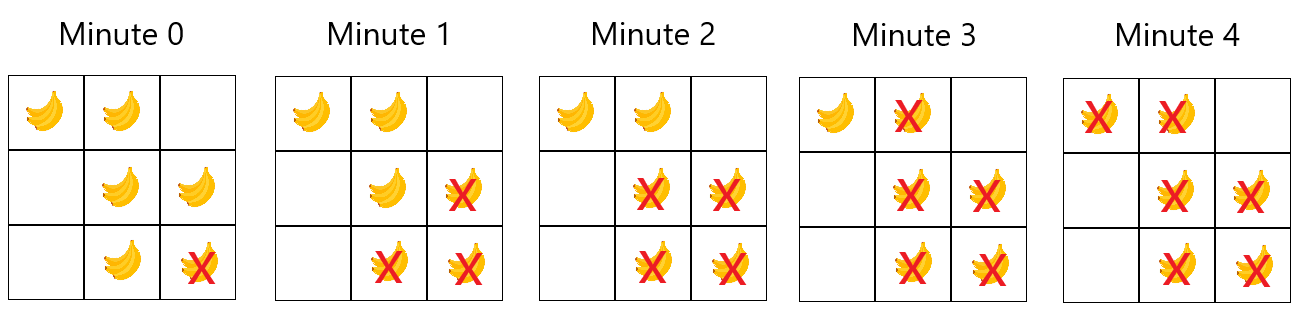
```java
Input: grid = [[1,1,0],[0,1,1],[0,1,2]]
Output: 4
```
**Example 2:**
```java
Input: grid = [[1,0,1],[0,2,0],[1,0,1]]
Output: -1
```
**Constraints:**
* `1 <= grid.length, grid[i].length <= 10`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m * n)</code> time and <code>O(m * n)</code> space, where <code>m</code> is the number of rows and <code>n</code> is the number of columns in the given grid.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
The DFS algorithm is not suitable for this problem because it explores nodes deeply rather than level by level. In this scenario, we need to determine which oranges rot at each second, which naturally fits a level-by-level traversal. Can you think of an algorithm designed for such a traversal?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Breadth First Search (BFS) algorithm. At each second, we rot the oranges that are adjacent to the rotten ones. So, we store the rotten oranges in a queue and process them in one go. The time at which a fresh orange gets rotten is the level at which it is visited. How would you implement it?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We traverse the grid and store the rotten oranges in a queue. We then run a BFS, processing the current level of rotten oranges and visiting the adjacent cells of each rotten orange. We only insert the adjacent cell into the queue if it contains a fresh orange. This process continues until the queue is empty. The level at which the BFS stops is the answer. However, we also need to check whether all oranges have rotted by traversing the grid. If any fresh orange is found, we return <code>-1</code>; otherwise, we return the level.
</p>
</details>
Medium
Not Attempted
Video
6
Pacific Atlantic Water Flow
You are given a rectangular island `heights` where `heights[r][c]` represents the **height above sea level** of the cell at coordinate `(r, c)`.
The islands borders the **Pacific Ocean** from the top and left sides, and borders the **Atlantic Ocean** from the bottom and right sides.
Water can flow in **four directions** (up, down, left, or right) from a cell to a neighboring cell with **height equal or lower**. Water can also flow into the ocean from cells adjacent to the ocean.
Find all cells where water can flow from that cell to **both** the Pacific and Atlantic oceans. Return it as a **2D list** where each element is a list `[r, c]` representing the row and column of the cell. You may return the answer in **any order**.
**Example 1:**

```java
Input: heights = [
[4,2,7,3,4],
[7,4,6,4,7],
[6,3,5,3,6]
]
Output: [[0,2],[0,4],[1,0],[1,1],[1,2],[1,3],[1,4],[2,0]]
```
**Example 2:**
```java
Input: heights = [[1],[1]]
Output: [[0,0],[0,1]]
```
**Constraints:**
* `1 <= heights.length, heights[r].length <= 100`
* `0 <= heights[r][c] <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m * n)</code> time and <code>O(m * n)</code> space, where <code>m</code> is the number of rows and <code>n</code> is the number of columns in the grid.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would be to traverse each cell in the grid and run a BFS from each cell to check if it can reach both oceans. This would result in an <code>O((m * n)^2)</code> solution. Can you think of a better way? Maybe you should consider a reverse way of traversing.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm starting from the border cells of the grid. However, we reverse the condition such that the next visiting cell should have a height greater than or equal to the current cell. For the top and left borders connected to the Pacific Ocean, we use a hash set called <code>pacific</code> and run a DFS from each of these cells, visiting nodes recursively. Similarly, for the bottom and right borders connected to the Atlantic Ocean, we use a hash set called <code>atlantic</code> and run a DFS. The required coordinates are the cells that exist in both the <code>pacific</code> and <code>atlantic</code> sets. How do you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We perform DFS from the border cells, using their respective hash sets. During the DFS, we recursively visit the neighbouring cells that are unvisited and have height greater than or equal to the current cell's height and add the current cell's coordinates to the corresponding hash set. Once the DFS completes, we traverse the grid and check if a cell exists in both the hash sets. If so, we add that cell to the result list.
</p>
</details>
Medium
Not Attempted
Video
7
Surrounded Regions
You are given a 2-D matrix `board` containing `'X'` and `'O'` characters.
If a continous, four-directionally connected group of `'O'`s is surrounded by `'X'`s, it is considered to be **surrounded**.
Change all **surrounded** regions of `'O'`s to `'X'`s and do so **in-place** by modifying the input board.
**Example 1:**
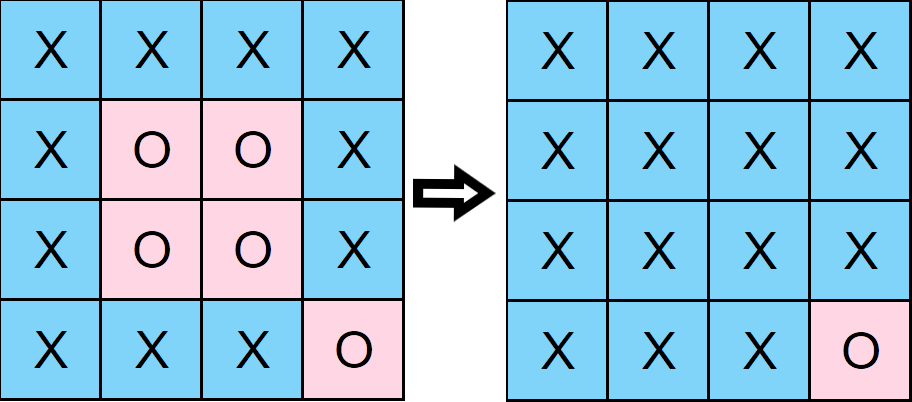
```java
Input: board = [
["X","X","X","X"],
["X","O","O","X"],
["X","O","O","X"],
["X","X","X","O"]
]
Output: [
["X","X","X","X"],
["X","X","X","X"],
["X","X","X","X"],
["X","X","X","O"]
]
```
Explanation: Note that regions that are on the border are not considered surrounded regions.
**Constraints:**
* `1 <= board.length, board[i].length <= 200`
* `board[i][j]` is `'X'` or `'O'`.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m * n)</code> time and <code>O(m * n)</code> space, where <code>m</code> is the number of rows and <code>n</code> is the number of columns in the matrix.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
We observe that we need to capture the regions that are not connected to the <code>O</code>'s on the border of the matrix. This means there should be no path connecting the <code>O</code>'s on the border to any <code>O</code>'s in the region. Can you think of a way to check the region connected to these border <code>O</code>'s?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (<code>DFS</code>) algorithm. Instead of checking the region connected to the border <code>O</code>'s, we can reverse the approach and mark the regions that are reachable from the border <code>O</code>'s. How would you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We run the DFS from every <code>'O'</code> on the border of the matrix, visiting the neighboring cells that are equal to <code>'O'</code> recursively and marking them as <code>'#'</code> to avoid revisiting. After completing all the DFS calls, we traverse the matrix again and capture the cells where <code>matrix[i][j] == 'O'</code>, and unmark the cells back to <code>'O'</code> where <code>matrix[i][j] == '#'</code>.
</p>
</details>
Medium
Not Attempted
Video
8
Course Schedule
You are given an array `prerequisites` where `prerequisites[i] = [a, b]` indicates that you **must** take course `b` first if you want to take course `a`.
The pair `[0, 1]`, indicates that must take course `1` before taking course `0`.
There are a total of `numCourses` courses you are required to take, labeled from `0` to `numCourses - 1`.
Return `true` if it is possible to finish all courses, otherwise return `false`.
**Example 1:**
```java
Input: numCourses = 2, prerequisites = [[0,1]]
Output: true
```
Explanation: First take course 1 (no prerequisites) and then take course 0.
**Example 2:**
```java
Input: numCourses = 2, prerequisites = [[0,1],[1,0]]
Output: false
```
Explanation: In order to take course 1 you must take course 0, and to take course 0 you must take course 1. So it is impossible.
**Constraints:**
* `1 <= numCourses <= 1000`
* `0 <= prerequisites.length <= 1000`
* `prerequisites[i].length == 2`
* `0 <= a[i], b[i] < numCourses`
* All `prerequisite` pairs are **unique**.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(V + E)</code> time and <code>O(V + E)</code> space, where <code>V</code> is the number of courses (nodes) and <code>E</code> is the number of prerequisites (edges).
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Consider the problem as a graph where courses represent the nodes, and <code>prerequisite[i] = [a, b]</code> represents a directed edge from <code>a</code> to <code>b</code>. We need to determine whether the graph contains a cycle. Why? Because if there is a cycle, it is impossible to complete the courses involved in the cycle. Can you think of an algorithm to detect cycle in a graph?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to detect a cycle in a graph. We iterate over each course, run a DFS from that course, and first try to finish its prerequisite courses by recursively traversing through them. To detect a cycle, we initialize a hash set called <code>path</code>, which contains the nodes visited in the current DFS call. If we encounter a course that is already in the <code>path</code>, we can conclude that a cycle is detected. How would you implement it?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We run a DFS starting from each course by initializing a hash set, <code>path</code>, to track the nodes in the current DFS call. At each step of the DFS, we return <code>false</code> if the current node is already in the <code>path</code>, indicating a cycle. We recursively traverse the neighbors of the current node, and if any of the neighbor DFS calls detect a cycle, we immediately return <code>false</code>. Additionally, we clear the neighbors list of a node when no cycle is found from that node to avoid revisiting those paths again.
</p>
</details>
Medium
Not Attempted
Video
9
Course Schedule II
You are given an array `prerequisites` where `prerequisites[i] = [a, b]` indicates that you **must** take course `b` first if you want to take course `a`.
* For example, the pair `[0, 1]`, indicates that to take course `0` you have to first take course `1`.
There are a total of `numCourses` courses you are required to take, labeled from `0` to `numCourses - 1`.
Return a valid ordering of courses you can take to finish all courses. If there are many valid answers, return **any** of them. If it's not possible to finish all courses, return an **empty array**.
**Example 1:**
```java
Input: numCourses = 3, prerequisites = [[1,0]]
Output: [0,1,2]
```
Explanation: We must ensure that course 0 is taken before course 1.
**Example 2:**
```java
Input: numCourses = 3, prerequisites = [[0,1],[1,2],[2,0]]
Output: []
```
Explanation: It's impossible to finish all courses.
**Constraints:**
* `1 <= numCourses <= 1000`
* `0 <= prerequisites.length <= 1000`
* All `prerequisite` pairs are **unique**.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(V + E)</code> time and <code>O(V + E)</code> space, where <code>V</code> is the number of courses (nodes) and <code>E</code> is the number of prerequisites (edges).
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Consider the problem as a graph where courses represent the nodes, and <code>prerequisite[i] = [a, b]</code> represents a directed edge from <code>a</code> to <code>b</code>. We need to determine whether the graph contains a cycle. Why? Because if there is a cycle, it is impossible to complete the courses involved in the cycle. Can you think of an algorithm to detect a cycle in a graph and also find the valid ordering if a cycle doesn't exist?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use DFS to detect a cycle in a graph. However, we also need to find the valid ordering of the courses, which can also be achieved using DFS. Alternatively, we can use the Topological Sort algorithm to find the valid ordering in this directed graph, where the graph must be acyclic to complete all the courses, and the prerequisite of a course acts as the parent node of that course. How would you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We compute the indegrees of all the nodes. Then, we perform a BFS starting from the nodes that have no parents (<code>indegree[node] == 0</code>). At each level, we traverse these nodes, decrement the indegree of their child nodes, and append those child nodes to the queue if their indegree becomes <code>0</code>. We only append nodes whose indegree is <code>0</code> or becomes <code>0</code> during the BFS to our result array. If the length of the result array is not equal to the number of courses, we return an empty array.
</p>
</details>
Medium
Not Attempted
Video
10
Graph Valid Tree
Given `n` nodes labeled from `0` to `n - 1` and a list of **undirected** edges (each edge is a pair of nodes), write a function to check whether these edges make up a valid tree.
**Example 1:**
```java
Input:
n = 5
edges = [[0, 1], [0, 2], [0, 3], [1, 4]]
Output:
true
```
**Example 2:**
```java
Input:
n = 5
edges = [[0, 1], [1, 2], [2, 3], [1, 3], [1, 4]]
Output:
false
```
**Note:**
* You can assume that no duplicate edges will appear in edges. Since all edges are `undirected`, `[0, 1]` is the same as `[1, 0]` and thus will not appear together in edges.
**Constraints:**
* `1 <= n <= 100`
* `0 <= edges.length <= n * (n - 1) / 2`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(V + E)</code> time and <code>O(V + E)</code> space, where <code>V</code> is the number vertices and <code>E</code> is the number of edges in the graph.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
According to the definition of a tree, a tree is an undirected graph with no cycles, all the nodes are connected as one component, and any two nodes have exactly one path. Can you think of a recursive algorithm to detect a cycle in the given graph and ensure it is a tree?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to detect a cycle in the graph. Since a tree has only one component, we can start the DFS from any node, say node <code>0</code>. During the traversal, we recursively visit its neighbors (children). If we encounter any already visited node that is not the parent of the current node, we return false as it indicates a cycle. How would you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We start DFS from node <code>0</code>, assuming <code>-1</code> as its parent. We initialize a hash set <code>visit</code> to track the visited nodes in the graph. During the DFS, we first check if the current node is already in <code>visit</code>. If it is, we return false, detecting a cycle. Otherwise, we mark the node as visited and perform DFS on its neighbors, skipping the parent node to avoid revisiting it. After all DFS calls, if we have visited all nodes, we return true, as the graph is connected. Otherwise, we return false because a tree must contain all nodes.
</p>
</details>
Medium
Not Attempted
Video
11
Number of Connected Components in an Undirected Graph
There is an undirected graph with `n` nodes. There is also an `edges` array, where `edges[i] = [a, b]` means that there is an edge between node `a` and node `b` in the graph.
The nodes are numbered from `0` to `n - 1`.
Return the total number of connected components in that graph.
**Example 1:**
```java
Input:
n=3
edges=[[0,1], [0,2]]
Output:
1
```
**Example 2:**
```java
Input:
n=6
edges=[[0,1], [1,2], [2,3], [4,5]]
Output:
2
```
**Constraints:**
* `1 <= n <= 100`
* `0 <= edges.length <= n * (n - 1) / 2`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(V + E)</code> time and <code>O(V + E)</code> space, where <code>V</code> is the number vertices and <code>E</code> is the number of edges in the graph.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Assume there are no edges initially, so we have <code>n</code> components, as there are that many nodes given. Now, we should add the given edges between the nodes. Can you think of an algorithm to add the edges between the nodes? Also, after adding an edge, how do you determine the number of components left?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Union-Find (DSU) algorithm to add the given edges. For simplicity, we use Union-Find by size, where we merge the smaller component into the larger one. The Union-Find algorithm inserts the edge only between two nodes from different components. It does not add the edge if the nodes are from the same component. How do you find the number of components after adding the edges? For example, consider that nodes <code>0</code> and <code>1</code> are not connected, so there are initially two components. After adding an edge between these nodes, they become part of the same component, leaving us with one component.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We create an object of the DSU and initialize the result variable <code>res = n</code>, which indicates that there are <code>n</code> components initially. We then iterate through the given edges. For each edge, we attempt to connect the nodes using the union function of the DSU. If the union is successful, we decrement <code>res</code>; otherwise, we continue. Finally, we return <code>res</code> as the number of components.
</p>
</details>
Medium
Not Attempted
Video
12
Redundant Connection
You are given a connected **undirected graph** with `n` nodes labeled from `1` to `n`. Initially, it contained no cycles and consisted of `n-1` edges.
We have now added one additional edge to the graph. The edge has two **different** vertices chosen from `1` to `n`, and was not an edge that previously existed in the graph.
The graph is represented as an array `edges` of length `n` where `edges[i] = [ai, bi]` represents an edge between nodes `ai` and `bi` in the graph.
Return an edge that can be removed so that the graph is still a connected non-cyclical graph. If there are multiple answers, return the edge that appears last in the input `edges`.
**Example 1:**
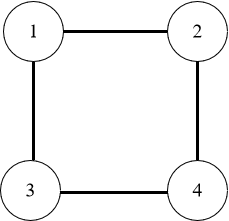
```java
Input: edges = [[1,2],[1,3],[3,4],[2,4]]
Output: [2,4]
```
**Example 2:**
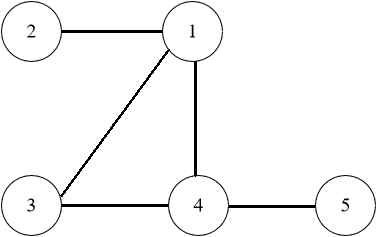
```java
Input: edges = [[1,2],[1,3],[1,4],[3,4],[4,5]]
Output: [3,4]
```
**Constraints:**
* `n == edges.length`
* `3 <= n <= 100`
* `1 <= edges[i][0] < edges[i][1] <= edges.length`
* There are no repeated edges and no self-loops in the input.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(V + E)</code> time and <code>O(V + E)</code> space, where <code>V</code> is the number vertices and <code>E</code> is the number of edges in the graph.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
There will be only one edge that creates the cycle in the given problem. Why? Because the graph is initially acyclic, and a cycle is formed only after adding one extra edge that was not present in the graph initially. Can you think of an algorithm that helps determine whether the current connecting edge forms a cycle? Perhaps a component-oriented algorithm?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Union-Find (DSU) algorithm to create the graph from the given edges. While connecting the edges, if we fail to connect any edge, it means this is the redundant edge, and we return it. How would you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We create an instance of the DSU object and traverse through the given edges. For each edge, we attempt to connect the nodes using the union function. If the union function returns <code>false</code>, indicating that the current edge forms a cycle, we immediately return that edge.
</p>
</details>
Medium
Not Attempted
Video
13
Word Ladder
You are given two words, `beginWord` and `endWord`, and also a list of words `wordList`. All of the given words are of the same length, consisting of lowercase English letters, and are all distinct.
Your goal is to transform `beginWord` into `endWord` by following the rules:
* You may transform `beginWord` to any word within `wordList`, provided that at exactly one position the words have a different character, and the rest of the positions have the same characters.
* You may repeat the previous step with the new word that you obtain, and you may do this as many times as needed.
Return the **minimum number of words within the transformation sequence** needed to obtain the `endWord`, or `0` if no such sequence exists.
**Example 1:**
```java
Input: beginWord = "cat", endWord = "sag", wordList = ["bat","bag","sag","dag","dot"]
Output: 4
```
Explanation: The transformation sequence is `"cat" -> "bat" -> "bag" -> "sag"`.
**Example 2:**
```java
Input: beginWord = "cat", endWord = "sag", wordList = ["bat","bag","sat","dag","dot"]
Output: 0
```
Explanation: There is no possible transformation sequence from `"cat"` to `"sag"` since the word `"sag"` is not in the wordList.
**Constraints:**
* `1 <= beginWord.length <= 10`
* `1 <= wordList.length <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O((m ^ 2) * n)</code> time and <code>O((m ^ 2) * n)</code> space, where <code>n</code> is the number of words and <code>m</code> is the length of the word.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Consider the given problem in terms of a graph, treating strings as nodes. Think of a way to build edges where two strings have an edge if they differ by a single character. A naive approach would be to consider each pair of strings and check whether an edge can be formed. Can you think of an efficient way? For example, consider a string <code>hot</code> and think about the strings that can be formed from it by changing a single letter.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
To efficiently build edges, consider transforming each word into intermediate states by replacing one character with a wildcard, like <code>*</code>. For example, the word <code>hot</code> can be transformed into <code>*ot</code>, <code>h*t</code>, and <code>ho*</code>. These intermediate states act as "parents" that connect words differing by one character. For instance, <code>*ot</code> can connect to words like <code>cot</code>. For each word in the list, generate all possible patterns by replacing each character with <code>*</code> and store the word as a child of these patterns. We can run a <code>BFS</code> starting from the <code>beginWord</code>, visiting other words while avoiding revisiting by using a hash set.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
When visiting a node during BFS, if the word matches the <code>endWord</code>, we immediately return <code>true</code>. Otherwise, we generate the pattern words that can be formed from the current word and attempt to visit the words connected to these pattern words. We add only unvisited words to the queue. If we exhaust all possibilities without finding the <code>endWord</code>, we return <code>false</code>.
</p>
</details>
Hard
Not Attempted
Video