
All Problems
7 problems1
Kth Largest Element in a Stream
Design a class to find the `kth` largest integer in a stream of values, including duplicates. E.g. the `2nd` largest from [1, 2, 3, 3] is `3`. The stream is not necessarily sorted.
Implement the following methods:
* `constructor(int k, int[] nums)` Initializes the object given an integer `k` and the stream of integers `nums`.
* `int add(int val)` Adds the integer `val` to the stream and returns the `kth` largest integer in the stream.
**Example 1:**
```java
Input:
["KthLargest", [3, [1, 2, 3, 3]], "add", [3], "add", [5], "add", [6], "add", [7], "add", [8]]
Output:
[null, 3, 3, 3, 5, 6]
Explanation:
KthLargest kthLargest = new KthLargest(3, [1, 2, 3, 3]);
kthLargest.add(3); // return 3
kthLargest.add(5); // return 3
kthLargest.add(6); // return 3
kthLargest.add(7); // return 5
kthLargest.add(8); // return 6
```
**Constraints:**
* `1 <= k <= 1000`
* `0 <= nums.length <= 1000`
* `-1000 <= nums[i] <= 1000`
* `-1000 <= val <= 1000`
* There will always be at least `k` integers in the stream when you search for the `kth` integer.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(mlogk)</code> time and <code>O(k)</code> space, where <code>m</code> is the number of times <code>add()</code> is called, and <code>k</code> represents the rank of the largest number to be tracked (i.e., the <code>k-th</code> largest element).
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve sorting the array in every time a number is added using <code>add()</code>, and then returning the <code>k-th</code> largest element. This would take <code>O(m * nlogn)</code> time, where <code>m</code> is the number of calls to <code>add()</code> and <code>n</code> is the total number of elements added. However, do we really need to track all the elements added, given that we only need the <code>k-th</code> largest element? Maybe you should think of a data structure which can maintain only the top <code>k</code> largest elements.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use a Min-Heap, which stores elements and keeps the smallest element at its top. When we add an element to the Min-Heap, it takes <code>O(logk)</code> time since we are storing <code>k</code> elements in it. Retrieving the top element (the smallest in the heap) takes <code>O(1)</code> time. How can this be useful for finding the <code>k-th</code> largest element?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
The <code>k-th</code> largest element is the smallest element among the top <code>k</code> largest elements. This means we only need to maintain <code>k</code> elements in our Min-Heap to efficiently determine the <code>k-th</code> largest element. Whenever the size of the Min-Heap exceeds <code>k</code>, we remove the smallest element by popping from the heap. How do you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We initialize a Min-Heap with the elements of the input array. When the <code>add()</code> function is called, we insert the new element into the heap. If the heap size exceeds <code>k</code>, we remove the smallest element (the root of the heap). Finally, the top element of the heap represents the <code>k-th</code> largest element and is returned.
</p>
</details>
Easy
Not Attempted
Video
2
Last Stone Weight
You are given an array of integers `stones` where `stones[i]` represents the weight of the `ith` stone.
We want to run a simulation on the stones as follows:
* At each step we choose the **two heaviest stones**, with weight `x` and `y` and smash them togethers
* If `x == y`, both stones are destroyed
* If `x < y`, the stone of weight `x` is destroyed, and the stone of weight `y` has new weight `y - x`.
Continue the simulation until there is no more than one stone remaining.
Return the weight of the last remaining stone or return `0` if none remain.
**Example 1:**
```java
Input: stones = [2,3,6,2,4]
Output: 1
```
Explanation:
We smash 6 and 4 and are left with a 2, so the array becomes [2,3,2,2].
We smash 3 and 2 and are left with a 1, so the array becomes [1,2,2].
We smash 2 and 2, so the array becomes [1].
**Example 2:**
```java
Input: stones = [1,2]
Output: 1
```
**Constraints:**
* `1 <= stones.length <= 20`
* `1 <= stones[i] <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(nlogn)</code> time and <code>O(n)</code> space, where <code>n</code> is the size of the input array.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive solution would involve simulating the process by sorting the array at each step and processing the top <code>2</code> heaviest stones, resulting in an <code>O(n * nlogn)</code> time complexity. Can you think of a better way? Consider using a data structure that efficiently supports insertion and removal of elements and maintain the sorted order.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use a Max-Heap, which allows us to retrieve the maximum element in <code>O(1)</code> time. We initially insert all the weights into the Max-Heap, which takes <code>O(logn)</code> time per insertion. We then simulate the process until only one or no element remains in the Max-Heap. At each step, we pop two elements from the Max-Heap which takes <code>O(logn)</code> time. If they are equal, we do not insert anything back into the heap and continue. Otherwise, we insert the difference of the two elements back into the heap.
</p>
</details>
Easy
Not Attempted
Video
3
K Closest Points to Origin
You are given an 2-D array `points` where `points[i] = [xi, yi]` represents the coordinates of a point on an X-Y axis plane. You are also given an integer `k`.
Return the `k` closest points to the origin `(0, 0)`.
The distance between two points is defined as the Euclidean distance (`sqrt((x1 - x2)^2 + (y1 - y2)^2))`.
You may return the answer in **any order**.
**Example 1:**
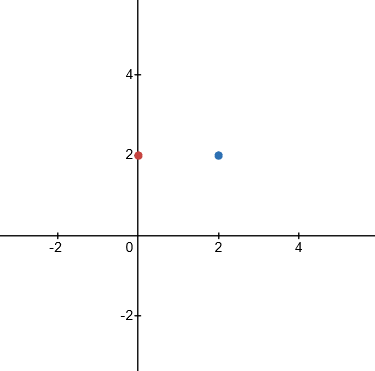
```java
Input: points = [[0,2],[2,2]], k = 1
Output: [[0,2]]
```
Explanation : The distance between `(0, 2)` and the origin `(0, 0)` is `2`. The distance between `(2, 2)` and the origin is `sqrt(2^2 + 2^2) = 2.82842`. So the closest point to the origin is `(0, 2)`.
**Example 2:**
```java
Input: points = [[0,2],[2,0],[2,2]], k = 2
Output: [[0,2],[2,0]]
```
Explanation: The output `[2,0],[0,2]` would also be accepted.
**Constraints:**
* `1 <= k <= points.length <= 1000`
* `-100 <= points[i][0], points[i][1] <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(nlogk)</code> time and <code>O(k)</code> space, where <code>n</code> is the size of the input array, and <code>k</code> is the number of points to be returned.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive solution would be to sort the array in ascending order based on the distances of the points from the origin <code>(0, 0)</code> and return the first <code>k</code> points. This would take <code>O(nlogn)</code> time. Can you think of a better way? Perhaps you could use a data structure that maintains only <code>k</code> points and allows efficient insertion and removal.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use a Max-Heap that keeps the maximum element at its top and allows retrieval in <code>O(1)</code> time. This data structure is ideal because we need to return the <code>k</code> closest points to the origin. By maintaining only <code>k</code> points in the heap, we can efficiently remove the farthest point when the size exceeds <code>k</code>. How would you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We initialize a Max-Heap that orders points based on their distances from the origin. Starting with an empty heap, we iterate through the array of points, inserting each point into the heap. If the size of the heap exceeds <code>k</code>, we remove the farthest point (the maximum element in the heap). After completing the iteration, the heap will contain the <code>k</code> closest points to the origin. Finally, we convert the heap into an array and return it.
</p>
</details>
Medium
Not Attempted
Video
4
Kth Largest Element in an Array
Given an unsorted array of integers `nums` and an integer `k`, return the `kth` largest element in the array.
By `kth` largest element, we mean the `kth` largest element in the sorted order, not the `kth` distinct element.
Follow-up: Can you solve it without sorting?
**Example 1:**
```java
Input: nums = [2,3,1,5,4], k = 2
Output: 4
```
**Example 2:**
```java
Input: nums = [2,3,1,1,5,5,4], k = 3
Output: 4
```
**Constraints:**
* `1 <= k <= nums.length <= 10000`
* `-1000 <= nums[i] <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(nlogk)</code> time and <code>O(k)</code> space, where <code>n</code> is the size of the input array, and <code>k</code> represents the rank of the largest number to be returned (i.e., the <code>k-th</code> largest element).
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive solution would be to sort the array in descending order and return the <code>k-th</code> largest element. This would be an <code>O(nlogn)</code> solution. Can you think of a better way? Maybe you should think of a data structure which can maintain only the top <code>k</code> largest elements.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use a Min-Heap, which stores elements and keeps the smallest element at its top. When we add an element to the Min-Heap, it takes <code>O(logk)</code> time since we are storing <code>k</code> elements in it. Retrieving the top element (the smallest in the heap) takes <code>O(1)</code> time. How can this be useful for finding the <code>k-th</code> largest element?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
The <code>k-th</code> largest element is the smallest element among the top <code>k</code> largest elements. This means we only need to maintain <code>k</code> elements in our Min-Heap to efficiently determine the <code>k-th</code> largest element. Whenever the size of the Min-Heap exceeds <code>k</code>, we remove the smallest element by popping from the heap. How do you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We initialize an empty Min-Heap. We iterate through the array and add elements to the heap. When the size of the heap exceeds <code>k</code>, we pop from the heap and continue. After the iteration, the top element of the heap is the <code>k-th</code> largest element.
</p>
</details>
Medium
Not Attempted
Video
5
Task Scheduler
You are given an array of CPU tasks `tasks`, where `tasks[i]` is an uppercase english character from `A` to `Z`. You are also given an integer `n`.
Each CPU cycle allows the completion of a single task, and tasks may be completed in any order.
The only constraint is that **identical** tasks must be separated by at least `n` CPU cycles, to cooldown the CPU.
Return the *minimum number* of CPU cycles required to complete all tasks.
**Example 1:**
```java
Input: tasks = ["X","X","Y","Y"], n = 2
Output: 5
```
Explanation: A possible sequence is: X -> Y -> idle -> X -> Y.
**Example 2:**
```java
Input: tasks = ["A","A","A","B","C"], n = 3
Output: 9
```
Explanation: A possible sequence is: A -> B -> C -> Idle -> A -> Idle -> Idle -> Idle -> A.
**Constraints:**
* `1 <= tasks.length <= 1000`
* `0 <= n <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m)</code> time and <code>O(1)</code> space, where <code>m</code> is the size of the input array.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
There are at most <code>26</code> different tasks, represented by <code>A</code> through <code>Z</code>. It is more efficient to count the frequency of each task and store it in a hash map or an array of size <code>26</code>. Can you think of a way to determine which task should be processed first?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We should always process the most frequent task first. After selecting the most frequent task, we must ensure that it is not processed again until after <code>n</code> seconds, due to the cooldown condition. Can you think of an efficient way to select the most frequent task and enforce the cooldown? Perhaps you could use a data structure that allows for <code>O(1)</code> time to retrieve the maximum element and another data structure to cooldown the processed tasks.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We can use a Max-Heap to efficiently retrieve the most frequent task at any given instance. However, to enforce the cooldown period, we must temporarily hold off from reinserting the processed task into the heap. This is where a queue data structure comes in handy. It helps maintain the order of processed tasks. Can you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We start by calculating the frequency of each task and initialize a variable <code>time</code> to track the total processing time. The task frequencies are inserted into a Max-Heap. We also use a queue to store tasks along with the time they become available after the cooldown. At each step, if the Max-Heap is empty, we update <code>time</code> to match the next available task in the queue, covering idle time. Otherwise, we process the most frequent task from the heap, decrement its frequency, and if it's still valid, add it back to the queue with its next available time. If the task at the front of the queue becomes available, we pop it and reinsert it into the heap.
</p>
</details>
Medium
Not Attempted
Video
6
Design Twitter
Implement a simplified version of Twitter which allows users to post tweets, follow/unfollow each other, and view the `10` most recent tweets within their own news feed.
Users and tweets are uniquely identified by their IDs (integers).
Implement the following methods:
* `Twitter()` Initializes the twitter object.
* `void postTweet(int userId, int tweetId)` Publish a new tweet with ID `tweetId` by the user `userId`. You may assume that each `tweetId` is unique.
* `List<Integer> getNewsFeed(int userId)` Fetches at most the `10` most recent tweet IDs in the user's news feed. Each item must be posted by users who the user is following or by the user themself. Tweets IDs should be **ordered from most recent to least recent**.
* `void follow(int followerId, int followeeId)` The user with ID `followerId` follows the user with ID `followeeId`.
* `void unfollow(int followerId, int followeeId)` The user with ID `followerId` unfollows the user with ID `followeeId`.
**Example 1:**
```java
Input:
["Twitter", "postTweet", [1, 10], "postTweet", [2, 20], "getNewsFeed", [1], "getNewsFeed", [2], "follow", [1, 2], "getNewsFeed", [1], "getNewsFeed", [2], "unfollow", [1, 2], "getNewsFeed", [1]]
Output:
[null, null, null, [10], [20], null, [20, 10], [20], null, [10]]
Explanation:
Twitter twitter = new Twitter();
twitter.postTweet(1, 10); // User 1 posts a new tweet with id = 10.
twitter.postTweet(2, 20); // User 2 posts a new tweet with id = 20.
twitter.getNewsFeed(1); // User 1's news feed should only contain their own tweets -> [10].
twitter.getNewsFeed(2); // User 2's news feed should only contain their own tweets -> [20].
twitter.follow(1, 2); // User 1 follows user 2.
twitter.getNewsFeed(1); // User 1's news feed should contain both tweets from user 1 and user 2 -> [20, 10].
twitter.getNewsFeed(2); // User 2's news feed should still only contain their own tweets -> [20].
twitter.unfollow(1, 2); // User 1 unfollows user 2.
twitter.getNewsFeed(1); // User 1's news feed should only contain their own tweets -> [10].
```
**Constraints:**
* `1 <= userId, followerId, followeeId <= 100`
* `0 <= tweetId <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(nlogn)</code> time for each <code>getNewsFeed()</code> function call, <code>O(1)</code> time for the remaining methods, and <code>O((N * m) + (N * M) + n)</code> space, where <code>n</code> is the number of <code>followeeIds</code> associated with the <code>userId</code>, <code>m</code> is the maximum number of tweets by any user, <code>N</code> is the total number of <code>userIds</code>, and <code>M</code> is the maximum number of followees for any user.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Can you think of a data structure to store all the information, such as <code>userIds</code> and corresponding <code>followeeIds</code>, or <code>userIds</code> and their tweets? Maybe you should think of a hash data structure in terms of key-value pairs. Also, can you think of a way to determine that a tweet was posted before another tweet?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We use a hash map <code>followMap</code> to store <code>userIds</code> and their unique <code>followeeIds</code> as a <code>hash set</code>. Another hash map, <code>tweetMap</code>, stores <code>userIds</code> and their tweets as a list of <code>(count, tweetId)</code> pairs. A counter <code>count</code>, incremented with each tweet, tracks the order of tweets. The variable <code>count</code> is helpful in distinguishing the time of tweets from two users. This way of storing data makes the functions <code>follow()</code>, <code>unfollow()</code>, and <code>postTweet()</code> run in <code>O(1)</code>. Can you think of a way to implement <code>getNewsFeed()</code>? Maybe consider a brute force approach and try to optimize it.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
A naive solution would involve taking the tweets of the userId and its followeeIds into a list, sorting them in descending order based on their <code>count</code> values, and returning the top <code>10</code> tweets as the most recent ones. Can you think of a more efficient approach that avoids collecting all tweets and sorting? Perhaps consider a data structure and leverage the fact that each user's individual tweets list is already sorted.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We can use a Max-Heap to efficiently retrieve the top <code>10</code> most recent tweets. For each followee and the userId, we insert their most recent tweet from the <code>tweetMap</code> into the heap, along with the tweet's <code>count</code> and its index in the tweet list. This index is necessary because after processing a tweet, we can insert the next most recent tweet from the same user's list. By always pushing and popping tweets from the heap, we ensure that the <code>10</code> most recent tweets are retrieved without sorting all tweets.
</p>
</details>
Medium
Not Attempted
Video
7
Find Median From Data Stream
The **[median](https://en.wikipedia.org/wiki/Median)** is the middle value in a sorted list of integers. For lists of *even* length, there is no middle value, so the median is the [mean](https://en.wikipedia.org/wiki/Mean) of the two middle values.
For example:
* For `arr = [1,2,3]`, the median is `2`.
* For `arr = [1,2]`, the median is `(1 + 2) / 2 = 1.5`
Implement the MedianFinder class:
* `MedianFinder()` initializes the `MedianFinder` object.
* `void addNum(int num)` adds the integer `num` from the data stream to the data structure.
* `double findMedian()` returns the median of all elements so far.
**Example 1:**
```java
Input:
["MedianFinder", "addNum", "1", "findMedian", "addNum", "3" "findMedian", "addNum", "2", "findMedian"]
Output:
[null, null, 1.0, null, 2.0, null, 2.0]
Explanation:
MedianFinder medianFinder = new MedianFinder();
medianFinder.addNum(1); // arr = [1]
medianFinder.findMedian(); // return 1.0
medianFinder.addNum(3); // arr = [1, 3]
medianFinder.findMedian(); // return 2.0
medianFinder.addNum(2); // arr[1, 2, 3]
medianFinder.findMedian(); // return 2.0
```
**Constraints:**
* `-100,000 <= num <= 100,000`
* `findMedian` will only be called after adding at least one integer to the data structure.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(logn)</code> time for <code>addNum()</code>, <code>O(1)</code> time for <code>findMedian()</code>, and <code>O(n)</code> space, where <code>n</code> is the current number of elements.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive solution would be to store the data stream in an array and sort it each time to find the median, resulting in <code>O(nlogn)</code> time for each <code>findMedian()</code> call. Can you think of a better way? Perhaps using a data structure that allows efficient insertion and retrieval of the median can make the solution more efficient.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
If we divide the array into two parts, we can find the median in <code>O(1)</code> if the left half can efficiently return the maximum and the right half can efficiently return the minimum. These values determine the median. However, the process changes slightly if the total number of elements is odd — in that case, the median is the element from the half with the larger size. Can you think of a data structure which is suitable to implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We can use a Heap (Max-Heap for the left half and Min-Heap for the right half). Instead of dividing the array, we store the elements in these heaps as they arrive in the data stream. But how can you maintain equal halves of elements in these two heaps? How do you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We initialize a Max-Heap and a Min-Heap. When adding an element, if the element is greater than the minimum element of the Min-Heap, we push it into the Min-Heap; otherwise, we push it into the Max-Heap. If the size difference between the two heaps becomes greater than one, we rebalance them by popping an element from the larger heap and pushing it into the smaller heap. This process ensures that the elements are evenly distributed between the two heaps, allowing us to retrieve the middle element or elements in <code>O(1)</code> time.
</p>
</details>
Hard
Not Attempted
Video