
All Problems
11 problems1
Reverse Linked List
Given the beginning of a singly linked list `head`, reverse the list, and return the new beginning of the list.
**Example 1:**
```java
Input: head = [0,1,2,3]
Output: [3,2,1,0]
```
**Example 2:**
```java
Input: head = []
Output: []
```
**Constraints:**
* `0 <= The length of the list <= 1000`.
* `-1000 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(1)</code> space, where <code>n</code> is the length of the given list.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would be to store the node values of the linked list into an array, then reverse the array, convert it back into a linked list, and return the new linked list's head. This would be an <code>O(n)</code> time solution but uses extra space. Can you think of a better way? Maybe there is an approach to reverse a linked list in place.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
As you can see, the head of the linked list becomes the tail after we reverse it. Can you think of an approach to change the references of the node pointers? Perhaps reversing a simple two-node list might help clarify the process.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
For example, consider a list <code>[2, 3]</code>, where <code>2</code> is the head of the list and <code>3</code> is the tail. When we reverse it, <code>3</code> becomes the new head, and its next pointer will point to <code>2</code>. Then, <code>2</code>'s next pointer will point to <code>null</code>. Can you figure out how to apply this approach to reverse a linked list of length <code>n</code> by iterating through it?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We can reverse the linked list in place by reversing the pointers between two nodes while keeping track of the next node's address. Before changing the next pointer of the current node, we must store the next node to ensure we don't lose the rest of the list during the reversal. This way, we can safely update the links between the previous and current nodes.
</p>
</details>
Easy
Not Attempted
Video
2
Merge Two Sorted Linked Lists
You are given the heads of two sorted linked lists `list1` and `list2`.
Merge the two lists into one **sorted** linked list and return the head of the new sorted linked list.
The new list should be made up of nodes from `list1` and `list2`.
**Example 1:**
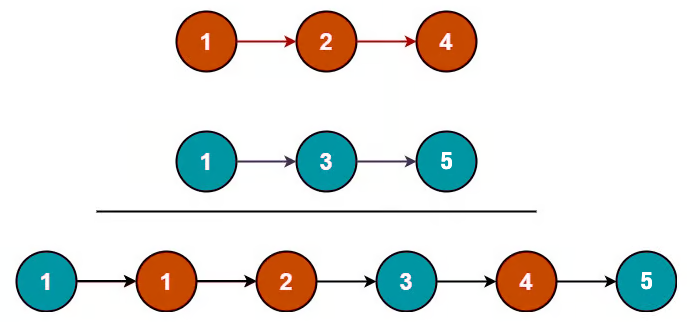
```java
Input: list1 = [1,2,4], list2 = [1,3,5]
Output: [1,1,2,3,4,5]
```
**Example 2:**
```java
Input: list1 = [], list2 = [1,2]
Output: [1,2]
```
**Example 3:**
```java
Input: list1 = [], list2 = []
Output: []
```
**Constraints:**
* `0 <= The length of the each list <= 100`.
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n + m)</code> time and <code>O(1)</code> space, where <code>n</code> is the length of <code>list1</code> and <code>m</code> is the length of <code>list2</code>.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve storing the values of both linked lists in an array, sorting the array, and then converting it back into a linked list. This approach would use <code>O(n)</code> extra space and is trivial. Can you think of a better way? Perhaps the sorted nature of the lists can be leveraged.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We create a dummy node to keep track of the head of the resulting linked list while iterating through the lists. Using <code>l1</code> and <code>l2</code> as iterators for <code>list1</code> and <code>list2</code>, respectively, we traverse both lists node by node to build a final linked list that is also sorted. How do you implement this?
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
For example, consider <code>list1 = [1, 2, 3]</code> and <code>list2 = [2, 3, 4]</code>. While iterating through the lists, we move the pointers by comparing the node values from both lists. We link the next pointer of the iterator to the node with the smaller value. For instance, when <code>l1 = 1</code> and <code>l2 = 2</code>, since <code>l1 < l2</code>, we point the iterator's next pointer to <code>l1</code> and proceed.
</p>
</p>
</details>
Easy
Not Attempted
Video
3
Linked List Cycle Detection
Given the beginning of a linked list `head`, return `true` if there is a cycle in the linked list. Otherwise, return `false`.
There is a cycle in a linked list if at least one node in the list can be visited again by following the `next` pointer.
Internally, `index` determines the index of the beginning of the cycle, if it exists. The tail node of the list will set it's `next` pointer to the `index-th` node. If `index = -1`, then the tail node points to `null` and no cycle exists.
**Note:** `index` is **not** given to you as a parameter.
**Example 1:**
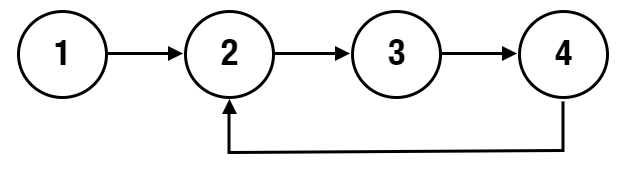
```java
Input: head = [1,2,3,4], index = 1
Output: true
```
Explanation: There is a cycle in the linked list, where the tail connects to the 1st node (0-indexed).
**Example 2:**
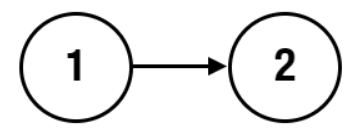
```java
Input: head = [1,2], index = -1
Output: false
```
**Constraints:**
* `1 <= Length of the list <= 1000`.
* `-1000 <= Node.val <= 1000`
* `index` is `-1` or a valid index in the linked list.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(1)</code> space, where <code>n</code> is the length of the given list.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive approach would be to use a hash set, which takes <code>O(1)</code> time to detect duplicates. Although this solution is acceptable, it requires <code>O(n)</code> extra space. Can you think of a better solution that avoids using extra space? Maybe there is an efficient algorithm which uses two pointers.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the fast and slow pointers technique, which is primarily used to detect cycles in a linked list. We iterate through the list using two pointers. The slow pointer moves one step at a time, while the fast pointer moves two steps at a time. If the list has a cycle, these two pointers will eventually meet. Why does this work?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
When there is no cycle in the list, the loop ends when the fast pointer becomes <code>null</code>. If a cycle exists, the fast pointer moves faster and continuously loops through the cycle. With each step, it reduces the gap between itself and the slow pointer by one node. For example, if the gap is <code>10</code>, the slow pointer moves by <code>1</code>, increasing the gap to <code>11</code>, while the fast pointer moves by <code>2</code>, reducing the gap to <code>9</code>. This process continues until the fast pointer catches up to the slow pointer, confirming a cycle.
</p>
</details>
Easy
Not Attempted
Video
4
Reorder Linked List
You are given the head of a singly linked-list.
The positions of a linked list of `length = 7` for example, can intially be represented as:
`[0, 1, 2, 3, 4, 5, 6]`
Reorder the nodes of the linked list to be in the following order:
`[0, 6, 1, 5, 2, 4, 3]`
Notice that in the general case for a list of `length = n` the nodes are reordered to be in the following order:
`[0, n-1, 1, n-2, 2, n-3, ...]`
You may not modify the values in the list's nodes, but instead you must reorder the nodes themselves.
**Example 1:**
```java
Input: head = [2,4,6,8]
Output: [2,8,4,6]
```
**Example 2:**
```java
Input: head = [2,4,6,8,10]
Output: [2,10,4,8,6]
```
**Constraints:**
* `1 <= Length of the list <= 1000`.
* `1 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(1)</code> space, where <code>n</code> is the length of the given list.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would be to store the node values of the list in an array, reorder the values, and create a new list. Can you think of a better way? Perhaps you can try reordering the nodes directly in place, avoiding the use of extra space.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
For example, consider the list <code>[1, 2, 3, 4, 5]</code>. To reorder the list, we connect the first and last nodes, then continue with the second and second-to-last nodes, and so on. Essentially, the list is split into two halves: the first half remains as is, and the second half is reversed and merged with the first half. For instance, <code>[1, 2]</code> will merge with the reversed <code>[5, 4, 3]</code>. Can you figure out a way to implement this reordering process? Maybe dividing the list into two halves could help.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We can divide the list into two halves using the fast and slow pointer approach, which helps identify the midpoint of the list. This allows us to split the list into two halves, with the heads labeled as <code>l1</code> and <code>l2</code>. Next, we reverse the second half (<code>l2</code>). After these steps, we proceed to reorder the two lists by iterating through them node by node, updating the next pointers accordingly.
</p>
</details>
Medium
Not Attempted
Video
5
Remove Node From End of Linked List
You are given the beginning of a linked list `head`, and an integer `n`.
Remove the `nth` node from the end of the list and return the beginning of the list.
**Example 1:**
```java
Input: head = [1,2,3,4], n = 2
Output: [1,2,4]
```
**Example 2:**
```java
Input: head = [5], n = 1
Output: []
```
**Example 3:**
```java
Input: head = [1,2], n = 2
Output: [2]
```
**Constraints:**
* The number of nodes in the list is `sz`.
* `1 <= sz <= 30`
* `0 <= Node.val <= 100`
* `1 <= n <= sz`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(N)</code> time and <code>O(1)</code> space, where <code>N</code> is the length of the given list.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve storing the nodes of the list into an array, removing the <code>nth</code> node from the array, and then converting the array back into a linked list to return the new head. However, this requires <code>O(N)</code> extra space. Can you think of a better approach to avoid using extra space? Maybe you should first solve with a two pass approach.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use a two-pass approach by first finding the length of the list, <code>N</code>. Since removing the <code>nth</code> node from the end is equivalent to removing the <code>(N - n)th</code> node from the front, as they both mean the same. How can you remove the node in a linked list?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
For example, consider a three-node list <code>[1, 2, 3]</code>. If we want to remove <code>2</code>, we update the <code>next</code> pointer of <code>1</code> (initially pointing to <code>2</code>) to point to the node after <code>2</code>, which is <code>3</code>. After this operation, the list becomes <code>[1, 3]</code>, and we return the head. But, can we think of a more better approach? Maybe a greedy calculation can help.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We can solve this in one pass using a greedy approach. Move the <code>first</code> pointer <code>n</code> steps ahead. Then, start another pointer <code>second</code> at the head and iterate both pointers simultaneously until <code>first</code> reaches <code>null</code>. At this point, the <code>second</code> pointer is just before the node to be removed. We then remove the node that is next to the <code>second</code> pointer. Why does this work?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 5</summary>
<p>
This greedy approach works because the <code>second</code> pointer is <code>n</code> nodes behind the <code>first</code> pointer. When the <code>first</code> pointer reaches the end, the <code>second</code> pointer is exactly <code>n</code> nodes from the end. This positioning allows us to remove the <code>nth</code> node from the end efficiently.
</p>
</details>
Medium
Not Attempted
Video
6
Copy Linked List with Random Pointer
You are given the head of a linked list of length `n`. Unlike a singly linked list, each node contains an additional pointer `random`, which may point to any node in the list, or `null`.
Create a **deep copy** of the list.
The deep copy should consist of exactly `n` **new** nodes, each including:
* The original value `val` of the copied node
* A `next` pointer to the new node corresponding to the `next` pointer of the original node
* A `random` pointer to the new node corresponding to the `random` pointer of the original node
Note: None of the pointers in the new list should point to nodes in the original list.
*Return the head of the copied linked list.*
In the examples, the linked list is represented as a list of `n` nodes. Each node is represented as a pair of `[val, random_index]` where `random_index` is the index of the node (0-indexed) that the `random` pointer points to, or `null` if it does not point to any node.
**Example 1:**
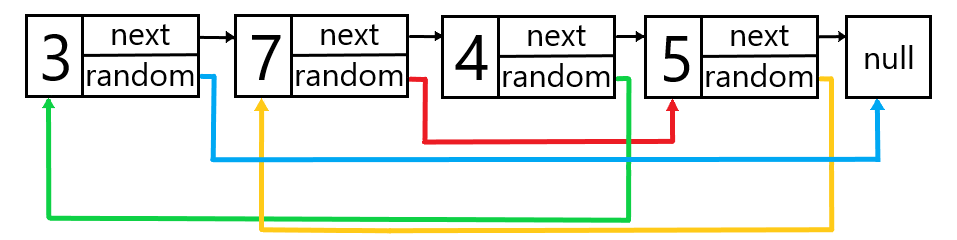
```java
Input: head = [[3,null],[7,3],[4,0],[5,1]]
Output: [[3,null],[7,3],[4,0],[5,1]]
```
**Example 2:**

```java
Input: head = [[1,null],[2,2],[3,2]]
Output: [[1,null],[2,2],[3,2]]
```
**Constraints:**
* `0 <= n <= 100`
* `-100 <= Node.val <= 100`
* `random` is `null` or is pointing to some node in the linked list.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the length of the given list.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
There is an extra random pointer for each node, and unlike the next pointer, which points to the next node, the random pointer can point to any random node in the list. A deep copy is meant to create completely separate nodes occupying different memory. Why can't we build a new list while iterating through the original list?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
Because, while iterating through the list, when we encounter a node and create a copy of it, we can't immediately assign the random pointer's address. This is because the random pointer might point to a node that has not yet been created. To solve this, we can first create copies of all the nodes in one iteration. However, we still can't directly assign the random pointers since we don't have the addresses of the copies of those random pointers. Can you think of a data structure to store this information? Maybe a hash data structure could help.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We can use a hash data structure, such as a hash map, which takes <code>O(1)</code> time to retrieve data. This can help by mapping the original nodes to their corresponding copies. This way, we can easily retrieve the copy of any node and assign the random pointers in a subsequent pass after creating copies of all nodes in the first pass.
</p>
</details>
Medium
Not Attempted
Video
7
Add Two Numbers
You are given two **non-empty** linked lists, `l1` and `l2`, where each represents a non-negative integer.
The digits are stored in **reverse order**, e.g. the number 321 is represented as `1 -> 2 -> 3 ->` in the linked list.
Each of the nodes contains a single digit. You may assume the two numbers do not contain any leading zero, except the number `0` itself.
Return the sum of the two numbers as a linked list.
**Example 1:**
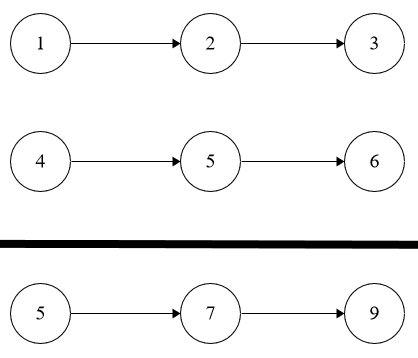
```java
Input: l1 = [1,2,3], l2 = [4,5,6]
Output: [5,7,9]
Explanation: 321 + 654 = 975.
```
**Example 2:**
```java
Input: l1 = [9], l2 = [9]
Output: [8,1]
```
**Constraints:**
* `1 <= l1.length, l2.length <= 100`.
* `0 <= Node.val <= 9`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(m + n)</code> time and <code>O(1)</code> space, where <code>m</code> is the length of list <code>l1</code> and <code>n</code> is the length of list <code>l2</code>.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Try to visualize the addition of two numbers. We know that the addition of two numbers is done by starting at the one's digit. We add the numbers by going through digit by digit. We track the extra value as a <code>carry</code> because the addition of two digits can result in a number with two digits. The <code>carry</code> is then added to the next digits, and so on. How do you implement this in case of linked lists?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We track the extra value, <code>carry</code>, here as well. We iterate through the lists <code>l1</code> and <code>l2</code> until both lists reach <code>null</code>. We add the values of both nodes as well as the carry. If either of the nodes is <code>null</code>, we add <code>0</code> in its place and continue the process while tracking the carry simultaneously. Once we complete the process, if we are left with any <code>carry</code>, we add an extra node with that carry value and return the head of the result list.
</p>
</details>
Medium
Not Attempted
Video
8
Find the Duplicate Number
You are given an array of integers `nums` containing `n + 1` integers. Each integer in `nums` is in the range `[1, n]` inclusive.
Every integer appears **exactly once**, except for one integer which appears **two or more times**. Return the integer that appears more than once.
**Example 1:**
```java
Input: nums = [1,2,3,2,2]
Output: 2
```
**Example 2:**
```java
Input: nums = [1,2,3,4,4]
Output: 4
```
Follow-up: Can you solve the problem **without** modifying the array `nums` and using $O(1)$ extra space?
**Constraints:**
* `1 <= n <= 10000`
* `nums.length == n + 1`
* `1 <= nums[i] <= n`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(1)</code> space, where <code>n</code> is the size of the input array.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive approach would be to use a hash set, which takes <code>O(1)</code> time to detect duplicates. Although this solution is acceptable, it requires <code>O(n)</code> extra space. Can you think of a better solution that avoids using extra space? Consider that the elements in the given array <code>nums</code> are within the range <code>1</code> to <code>len(nums)</code>.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the given input array itself as a hash set without creating a new one. This can be achieved by marking the positions (<code>0</code>-indexed) corresponding to the elements that have already been encountered. Can you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We iterate through the array using index <code>i</code>. For each element, we use its absolute value to find the corresponding index and mark that position as negative: <code>nums[abs(nums[i]) - 1] *= -1</code>. Taking absolute value ensures we work with the original value even if it’s already negated. How can you detect duplicates?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
For example, in the array <code>[2, 1, 2, 3]</code>, where <code>2</code> is repeated, we mark the index corresponding to each element as negative. If we encounter a number whose corresponding position is already negative, it means the number is a duplicate, and we return it.
</p>
</details>
Medium
Not Attempted
Video
9
LRU Cache
Implement the [Least Recently Used (LRU)](https://en.wikipedia.org/wiki/Cache_replacement_policies#LRU) cache class `LRUCache`. The class should support the following operations
* `LRUCache(int capacity)` Initialize the LRU cache of size `capacity`.
* `int get(int key)` Return the value corresponding to the `key` if the `key` exists, otherwise return `-1`.
* `void put(int key, int value)` Update the `value` of the `key` if the `key` exists. Otherwise, add the `key`-`value` pair to the cache. If the introduction of the new pair causes the cache to exceed its capacity, remove the least recently used key.
A key is considered used if a `get` or a `put` operation is called on it.
Ensure that `get` and `put` each run in $O(1)$ average time complexity.
**Example 1:**
```java
Input:
["LRUCache", [2], "put", [1, 10], "get", [1], "put", [2, 20], "put", [3, 30], "get", [2], "get", [1]]
Output:
[null, null, 10, null, null, 20, -1]
Explanation:
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 10); // cache: {1=10}
lRUCache.get(1); // return 10
lRUCache.put(2, 20); // cache: {1=10, 2=20}
lRUCache.put(3, 30); // cache: {2=20, 3=30}, key=1 was evicted
lRUCache.get(2); // returns 20
lRUCache.get(1); // return -1 (not found)
```
**Constraints:**
* `1 <= capacity <= 100`
* `0 <= key <= 1000`
* `0 <= value <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(1)</code> time for each <code>put()</code> and <code>get()</code> function call and an overall space of <code>O(n)</code>, where <code>n</code> is the capacity of the <code>LRU</code> cache.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Can you think of a data structure for storing data in key-value pairs? Maybe a hash-based data structure with unique keys.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use a hash map which takes <code>O(1)</code> time to get and put the values. But, how can you deal with the least recently used to be removed criteria as a key is updated by the <code>put()</code> or recently used by the <code>get()</code> functions? Can you think of a data structure to store the order of values?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
A brute-force solution would involve maintaining the order of key-value pairs in an array list, performing operations by iterating through the list to erase and insert these key-value pairs. However, this would result in an <code>O(n)</code> time complexity. Can you think of a data structure that allows removing and reinserting elements in <code>O(1)</code> time?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We can use a doubly-linked list, which allows us to remove a node from the list when we have the address of that node. Can you think of a way to store these addresses so that we can efficiently remove or update a key when needed?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 5</summary>
<p>
We can use a doubly linked list where key-value pairs are stored as nodes, with the least recently used (LRU) node at the head and the most recently used (MRU) node at the tail. Whenever a key is accessed using <code>get()</code> or <code>put()</code>, we remove the corresponding node and reinsert it at the tail. When the cache reaches its capacity, we remove the LRU node from the head of the list. Additionally, we use a hash map to store each key and the corresponding address of its node, enabling efficient operations in <code>O(1)</code> time.
</p>
</details>
Medium
Not Attempted
Video
10
Merge K Sorted Linked Lists
You are given an array of `k` linked lists `lists`, where each list is sorted in ascending order.
Return the **sorted** linked list that is the result of merging all of the individual linked lists.
**Example 1:**
```java
Input: lists = [[1,2,4],[1,3,5],[3,6]]
Output: [1,1,2,3,3,4,5,6]
```
**Example 2:**
```java
Input: lists = []
Output: []
```
**Example 3:**
```java
Input: lists = [[]]
Output: []
```
**Constraints:**
* `0 <= lists.length <= 1000`
* `0 <= lists[i].length <= 100`
* `-1000 <= lists[i][j] <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(n * k)</code> time and <code>O(1)</code> space, where <code>k</code> is the total number of lists and <code>n</code> is the total number of nodes across all lists.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute-force solution would involve storing all <code>n</code> nodes in an array, sorting them, and converting the array back into a linked list, resulting in an <code>O(nlogn)</code> time complexity. Can you think of a better way? Perhaps consider leveraging the idea behind merging two sorted linked lists.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can merge two sorted linked lists without using any extra space. To handle <code>k</code> sorted linked lists, we can iteratively merge each linked list with a resultant merged list. How can you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We iterate through the list array with index <code>i</code>, starting at <code>i = 1</code>. We merge the linked lists using <code>mergeTwoLists(lists[i], lists[i - 1])</code>, which returns the head of the merged list. This head is stored in <code>lists[i]</code>, and the process continues. Finally, the merged list is obtained at the last index, and we return its head.
</p>
</details>
Hard
Not Attempted
Video
11
Reverse Nodes in K-Group
You are given the head of a singly linked list `head` and a positive integer `k`.
You must reverse the first `k` nodes in the linked list, and then reverse the next `k` nodes, and so on. If there are fewer than `k` nodes left, leave the nodes as they are.
Return the modified list after reversing the nodes in each group of `k`.
You are only allowed to modify the nodes' `next` pointers, not the values of the nodes.
**Example 1:**
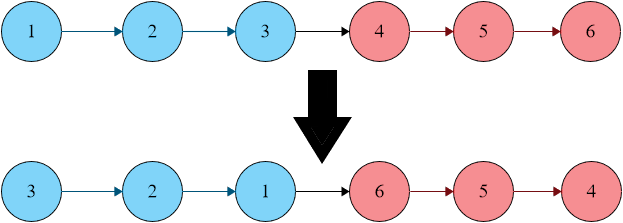
```java
Input: head = [1,2,3,4,5,6], k = 3
Output: [3,2,1,6,5,4]
```
**Example 2:**
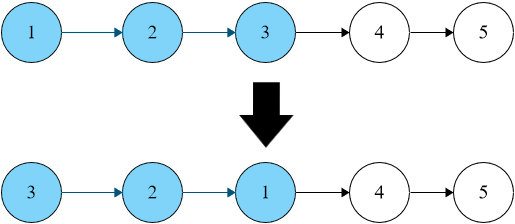
```java
Input: head = [1,2,3,4,5], k = 3
Output: [3,2,1,4,5]
```
**Constraints:**
* The length of the linked list is `n`.
* `1 <= k <= n <= 100`
* `0 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(1)</code> space, where <code>n</code> is the length of the given list.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute-force solution would involve storing the linked list node values in an array, reversing the <code>k</code> groups one by one, and then converting the array back into a linked list, requiring extra space of <code>O(n)</code>. Can you think of a better way? Perhaps you could apply the idea of reversing a linked list in-place without using extra space.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can avoid extra space by reversing each group in-place while keeping track of the head of the next group. For example, consider the list <code>[1, 2, 3, 4, 5]</code> with <code>k = 2</code>. First, we reverse the group <code>[1, 2]</code> to <code>[2, 1]</code>. Then, we reverse <code>[3, 4]</code>, resulting in <code>[2, 1, 4, 3, 5]</code>. While reversing <code>[3, 4]</code>, we need to link <code>1</code> to <code>4</code> and also link <code>3</code> to <code>5</code>. How can we efficiently manage these pointers?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We create a dummy node to handle modifications to the head of the linked list, pointing its <code>next</code> pointer to the current head. We then iterate <code>k</code> nodes, storing the address of the next group's head and tracking the tail of the previous group. After reversing the current group, we reconnect it by linking the previous group's tail to the new head and the current group's tail to the next group's head. This process is repeated for all groups, and we return the new head of the linked list.
</p>
</details>
Hard
Not Attempted
Video